Architecture¶
TODO: describe architecture
“Memory”¶
TODO: explain purpose of memory.json
Cache¶
Example¶
In a typical invocation, scrilla will filter the user input through several layers of caching before attempting to make an API call. For example, if a user enters the command
scrilla risk-profile ALLY BX SONY -start 2022-01-01 -end 2022-06-01
Then the following flow will execute,
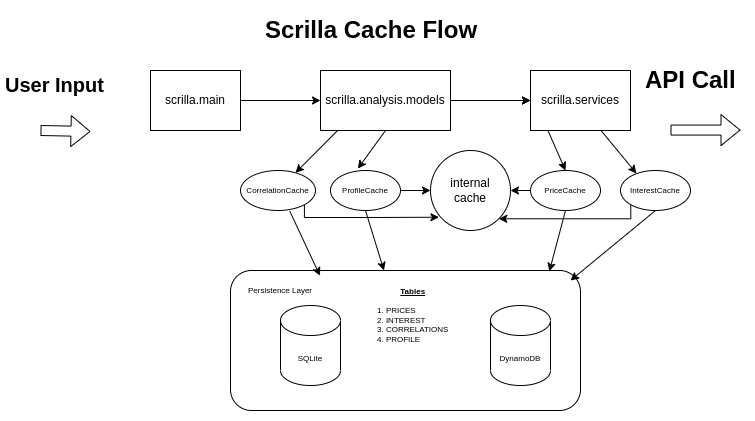
First, scrilla.main will parse and pass the arguments off to scrilla.analysis.models. scrilla.analysis.models will instruct the ProfileCache and CorrelationCache to search previous calculations for the current calculation. These caches will check an internal dict kept in memory for frequently assessed data; this is why each cache is implemented as a singleton: all instances of a given type of cache refer to the same instance, i.e. only one instance of each Cache can be created; this is so all references to a cache will in turn refer to the same internal cache.
If the result is not found in the internal cache, the ProfileCache and CorrelationCache will query the datastore. Either SQLite or DynamoDB will be used for the persistence layer, depending on the value of scrilla.settings.CACHE_MODE, which is in turn configured by the value of the CACHE_MODE environment variable. If this query returns the calculation, the flow halts and the result is passed back to the user.
If the query doesn’t return a result, scrilla.analysis.models will need to calculate the result, so it will request price data from scrilla.services.
Similar to the relationship between scrilla.analysis.models and the caches, ProfileCache and CorrelationCache, scrilla.services will instruct the PriceCache and InterestCache to search for the requested data. Each cache will check an internal dict where it stores frequently assessed data in memory. If a result is found, the program halts and returns the result to the user. If the internal cache returns nothing, PriceCache and InterestCache will query the datastore, either SQLite or DynamoDB as previously mentioned. If the result is found, the program halts and reutnrs the ressult to the user. If the query does not return a result, all of the caches have been exhausted, so scrilla.services will finally query the API service that acts as the source of truth for that particular piece of data (i.e., price data is retrieved from AlphaVantage, interest data is retrieved from the US Treasury, etc.)
Once the result is returned from the external API, the data will be persisted at every level as it flows back towards the user: PriceCache and InterestCache will save the result in their internal cache and upsert the data into the persistence layer. After scrilla.anaylsis.models receives the price data and calculates the relevant statistics, it will pass the results to CorrelationCache and ProfileCache, which will in turn save the results to the internal cache and then upsert the data into the persistence layer.
Once the cache is hydrated with data, any subsequent invocations that rely on the same data or calculations will hit the cache.
memory.json¶
memory.json is a file kept in the installation’s /data/common/ directory that contains flags to inform the application it has already executed certain actions, so it does not need to perform them again. With respect to the caches, this file has information about whether or not the cache tables have been initialized. Everytime one of the cache classes is instantiated, the cache will attempt to provision the tables in the persistence layer. This can be a costly operation, in terms of response time, especially since it only needs to be performed the first time the application executes. Therefore, once these tables are provisioned, the memory.json will be updated to reflect this information. Once the flags for the cache tables are set to True, the cache classes will skip the table provisioning step any time a new cache class is instantiated.
NOTE: Even though the cache classes are singletons, their __init__ methods are still invoked whenever they are instantiated, even if a previous instance exists. This is by design due to the fact the cache can be cleared via the scrilla.files module, i.e. the tables are dropped. In this case, the cache will need to re-create the tables in the persistence layer.